
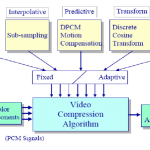
Instead of assuming a memoryless source, run – length coding (RLC) exploits memory present in the information source. It is one of the simplest forms of data compression. The basic idea is that if the information source we wish to compress has the property that symbols tend to form continuous groups, instead of coding each symbol in the group individually, we can code one such symbol and the length of the group.
As an example, consider a bilevel image (one with only 1 – bit black and white pixels) with monotone regions. This information source can be efficiently coded using run – length coding. In fact, since there are only two symbols, we do not even need to code any symbol at the start of each run. Instead, we can assume that the starting run is always of a particular color (either black or white) and simply code the length of each run.
The above description is the one – dimensional run – length coding algorithm. A two – dimensional variant of it is usually used to code bilevel images. This algorithm uses the coded run information in the previous row of the image to code the run in the current row.
Comments are closed