Arithmetic coding is a form of entropy encoding used in lossless data compression. Normally, a string of characters such as the words “hello there” is represented using a fixed number of bits per character, as in the ASCII code. When a string is converted to arithmetic encoding, frequently used characters will be stored with fewer bits and not – so – frequently occurring characters will be stored with more bits, resulting in fewer bits used in total. Arithmetic coding differs from other forms of entropy encoding such as Huffman coding in that rather than separating the input into component symbols and replacing each with a code, arithmetic coding encodes the entire message into a single number, a fraction n where (0.0 ≤ n< 1.0).
ALGORITHM ARITHMETIC CODING ENCODER
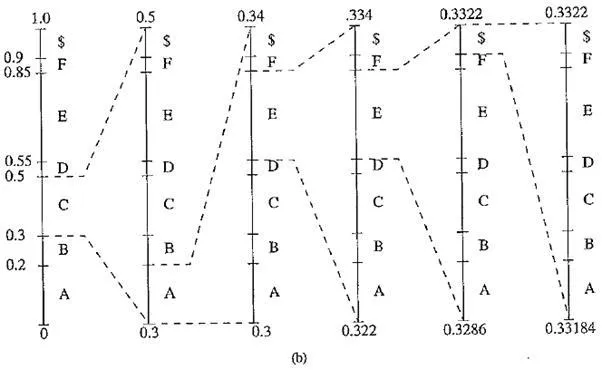
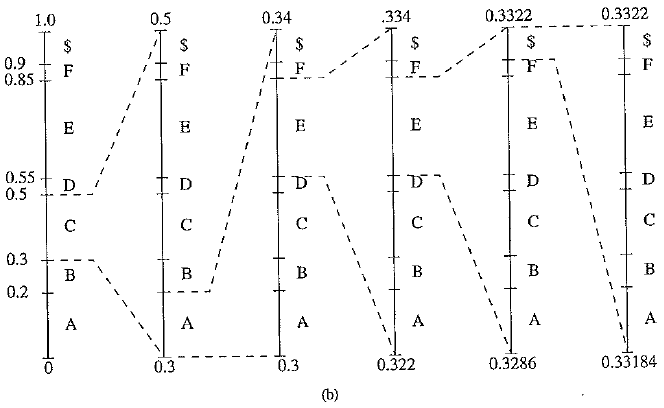
Arithmetic coding: encode symbols CAEE$: (a) probability distribution of symbols; (b) graphical display of shrinking ranges; (c) new low, high, and range generated

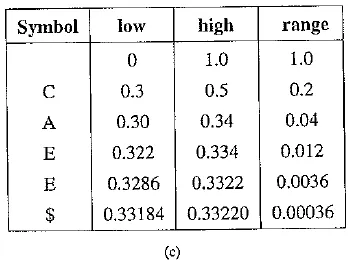
The encoding process is illustrated in the above figures (h) and (c), in which a string of symbols CAEE$ is encoded. Initially, low = 0, high ~ 1.0, and range = 1.0. After the first symbol C, Rangelow(C) = 0.3, Range Mgh(C) = 0.5; so low = 0 + 1.0 x 0.3 = 0.3, high — 0 + 1.0 x 0.5 = 0.5. The new range – is now reduced to 0.2.
For clarity of illustration, the ever – shrinking ranges are enlarged in each step (indicated by dashed lines) in figure (b). After the second symbol A, low, high, and range are 0.30, 0.34, and 0.04. The process repeats itself until after the terminating symbol $ is received. By then low and high are 0.33184 and 0.33220, respectively. It is apparent that finally we have range – Pc x PA x PE x PE x Ps = 0.2 x 0.2 x 0.3 X 0.3 x 0.1 = 0.00036
The final step in encoding calls for generation of a number that falls within the range [low, high). Although it is trivial to pick such a number in decimal, such as 0.33184, 0.33185, or 0.332 in the above example, it is less obvious how to do it with a binary fractional number. The following algorithm will ensure that the shortest binary codeword is found if low and high are the two ends of the range and low < high.
PROCEDURE Generating Codeword for Encoder

For the above example, low — 0.33184, high — 0.3322. If we assign 1 to the first binary fraction bit, it would be 0.1 in binary, and its decimal value(code) — value(0.l) = 0.5 > high. Hence, we assign 0 to the first bit. Since value(0.0) = 0 < low, the while loop continues.
Assigning 1 to the second bit makes a binary code 0.01 and value (0.01) = 0.25, which is less than high, so it is accepted. Since it is still true that value(0.0l) < low, the iteration continues. Eventually, the binary codeword generated is 0.01010101, which is 2 – 2 + 2 – 4 + 2 – 6 + 2 – 8 = 0.33203125.
It must be pointed out that we were lucky to have found a codeword of only 8 bits to represent this sequence of symbols CAEE$. In this case, log2 1 / PC + log2 1 / PA + log2 1 / PE + log2 1 / Pε + log2 1 / PS = log2 1 / range = log2 1 / 0.00036, which would suggest that it could take 12 bits to encode a string of symbols like this.
It can be proven that upper bound. Namely, in the worst case, the shortest codeword in arithmetic coding will require k bits to encode a sequence of symbols, and
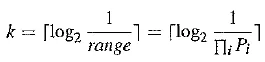
where Pi is the probability for symbol i and range is the final range generated by the encoder. Apparently, when the length of the message is long, its range quickly becomes very small, and hence log2 1 / range becomes very large; the difference between log2 1 / rangeand {log21 / range} is negligible.
Generally, Arithmetic Coding achieves better performance than Huffman coding, because the former treats an entire sequence of symbols as one unit, whereas the latter has the restriction of assigning an integral number of bits to each symbol. For example, Huffman coding would require 12 bits for CAEE$, equaling the worst – case performance of Arithmetic Coding.
Moreover, Huffman coding cannot always attain the upper bound illustrated in Eq. It can be shown (see Exercise ) that if the alphabet is [A, B, C] and the known probability distribution is Pa — 0.5, PB = 0.4, Pc = 0.1, then for sending BBB, Huffman coding will require 6 bits, which is more than, whereas arithmetic coding will need only 4 bits.
ALGORITHM ARITHMETIC CODING DECODER
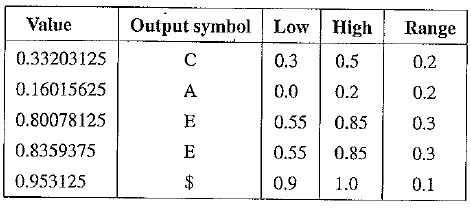
The following table illustrates the decoding process for the above example. Initially, value — 0.33203125. Since Range low(C) = 0.3 < 0.33203125 < 0.5 = Range high(C), the first output symbol is C. This yields value – [0.33203125 – 0.3J / 0.2 = 0.16015625, which in turn determines that the second symbol is A. Eventually, value is 0.953125, which falls in the range of the terminator $.
Table Arithmetic coding: decode symbols CAEE$
The algorithm described previously has a subtle implementation difficulty. When the intervals shrink, we need to use very high – precision numbers to do encoding. This makes practical implementation of this algorithm infeasible. Fortunately, it is possible to rescale the intervals and use only integer arithmetic for a practical implementation.
In the above discussion, a special symbol, $, is used as a terminator of the string of symbols. This is analogous to sending end – of – line (EOL) in image transmission. In conventional compression applications, no terminator symbol is needed, as the encoder simply codes all symbols from the input. However, if the transmission channel / network is noisy (lossy), the protection of having a terminator (or EOL) symbol is crucial for the decoder to regain synchronization with the encoder. The coding of the EOL symbol itself is an interesting problem. Usually, EOL ends up being relatively long.
